- IA-32 is a basic model we could use to understand about computer architectures before learning about more advanced 64 bit processors.
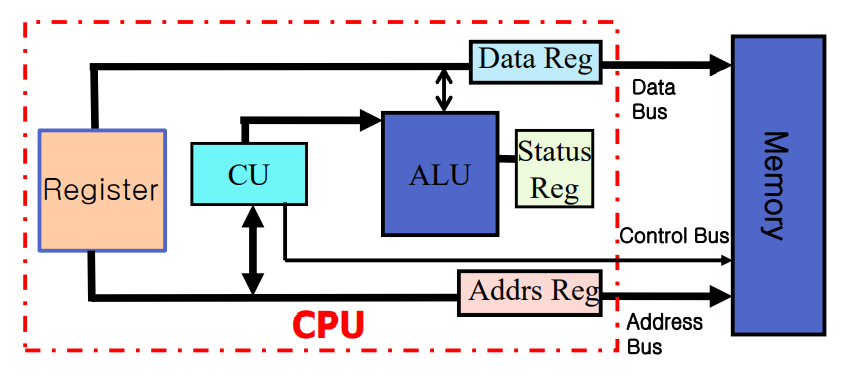
- As mentioned in previous articles, the job of the CPU is to succesfully perform the 'fetch -> decode -> execute cycle'.
- Every operation is synchronized by the clock.
- Each step in instruction cycle takes one clock cycle.
- Specifically, each process is processed simutaneously within the clock period like a conveyer belt in a factory.
- This is called multi-stage pipelining.
- IA-32 processors are pipelined with 6-stage execution cycle.
- 'Bus Interface Unit(BIU)' is memory access & I/O access
- 'Code fetch unit' is getting instructions from the BIU & putting into the I-queue.
- 'Decode Unit' is decoding instructions from I-queue and translating into micro-code.
- 'Execution unit' is executing micro-code instructions.
- 'Segment Unit' is translating logical address into linear address.
- 'Paging Unit' is translating linear address into physical address.
- Segment Unit and Paging Unit are units that match the logical units into physical units.
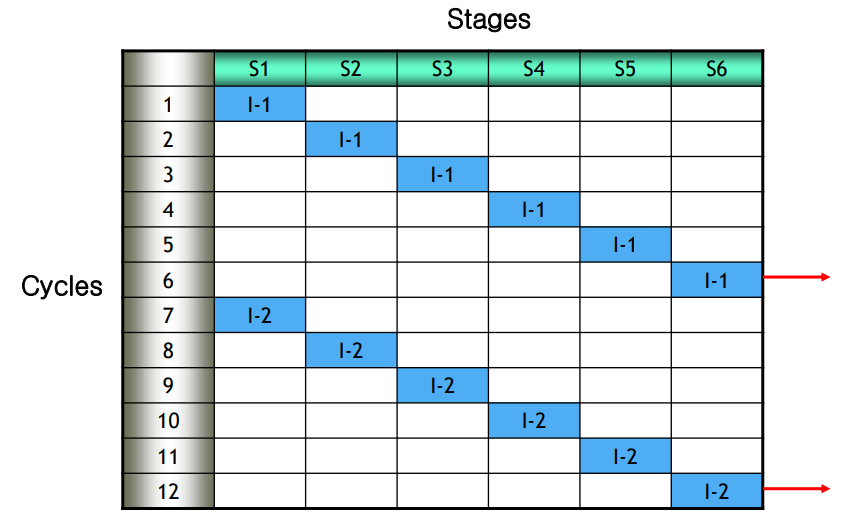
- If a processor is not pipelined it would be very inefficient.
- For k stages, it would take n*k cycles, which would be an waste of CPU.

- In the case of a pipelined processor, CPU is used much more efficiently.
- For k stages, it would take k+(n-1) cycles.
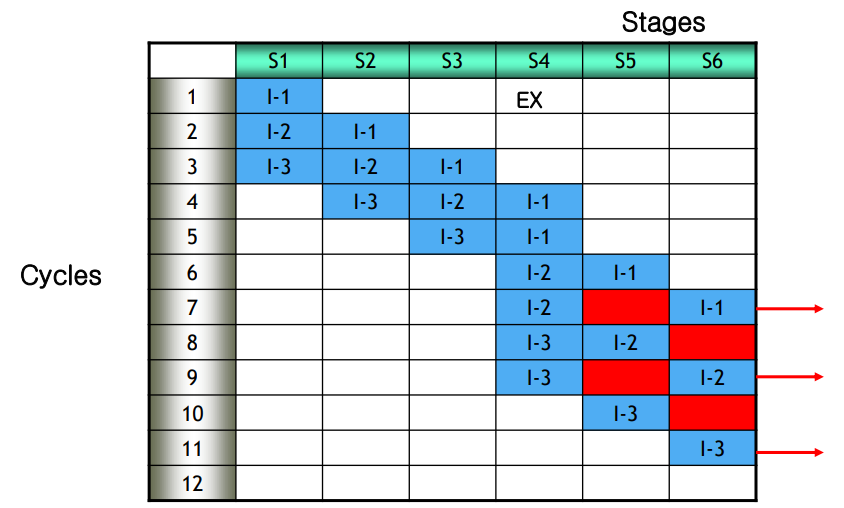
- A superscalar processor could deal with instructions that would require more than 2 cycles.
- For example, in S4, each process requires 2 cycles.
- For k-stages, n-instructions, it would take (k+2n-1) cycles in total.
- This leads to the problem that S5 doesn't have any process to do in cycle 7,9.

- To handle the problem mentioned above, we use u-pipeline and v-pipeline.
- We put two S4 processors each called S4-u, S4-v that would each handle odd numbered instructions and even numbered instructions.
- For k-stages, n-instructions, it would take (k+n) cycles in total.
- For multi-stage pipeline, the CPU has to fetch instructions from memory all the time.
- The big problem is that even if the memory is a critical component to execution speed, the performance gap between CPU and memory was huge.
- One way to solve this problem is to set a instruction queue for prefetch, so that when decoding, we could use the instruction queue instead of fetching it every time.
- Using memory hierarchy, with reasonable amount of resource, we can get the best performance of speed.
- The CPU controls the registers.
- The Cache memory does not have a object that controls it.
- The Main Memory is controlled by Operating system.
- The Disk is also controlled by Operating system.
- The 'Principle of Locality' is that a program access a relatively small portion of the address space at any instant of time.
- Two different types of locality is 'Temporal Locality(Locality in Time)', and 'Spatial Locality(Locality in Space)'.
- 'Temporal Locality(Locality in Time)' is that if an item is referenced, it will tend to be referenced again soon.
- 'Spatial Locality(Locality in Space)' is that if an item is referenced, items whose addresses are close by tend to be referenced soon.
- Cache Memory is also called SRAMs.
- Main Memory is also called DRAMs.
- When we need high speed memory, we use cache memory.
- L-1 cache exists inside the CPU.
- L-2 cache exists inside and outside the CPU.
- If the data to be read is already in cache memory, it is 'Cache hit', and when data to e read is not in cache memory, it is 'Cache miss'.
- The data should be cache hit when this data will be read frequently throughout processes in the future.
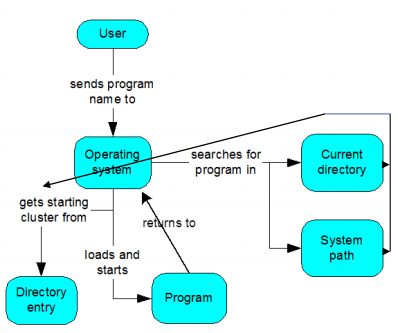
- After booting, Operating System controls a program.
- When we type a program name, OS search filename in current directory, and if found, retrieves file information.
- OS then determines next available location in memory to load program file into memory, and then branch to the first instruction of the file to process it.
- When the program is finished, Program removes file handle & memory space is allocated, and return to OS control.

- In 16-bit Intel Processor, there exists 16-bit registers which could be divided into general purpose, special purpose and hidden.
- AX(Accumulator), BX(Base register). CX(Counter register). DX(Data) are 16-bit general-purpose registers.
- AX, BX, CX, DX could be divided into AH, AL, BH, BL, CH, CL, DH, DL 8-bit general purpose registers.
- CS(Code segment), DS(Data segment), SS(Stack segment). ES(Extra segment) are segment registers.
- BP(Base Pointer), SP(Stack Pointer), SI(Source Index), DI(Destination Index) are index registers.
- IP(Instruction pointer), Flags(DF, CF, OF, SF, ZF, A, P) are a status/control registers.
- CS:IP(Segment + offset) form the complete address with segment + offset.

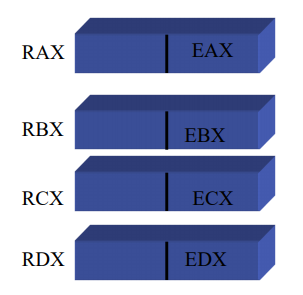
- 32-bit Intel Processor, 64-bit Intel Processor have slight changes, but overall have the same set of registers.
- It is crucial to have compatible mode when designing a new processor.

- Memory is divided into segments.
- A logical address notation is "<seg address> : <offset address>".
- For example, 60250 might be noted as 6000:0250.
- From 0000 - 003FFH, there exists interrupt vector table of 32-bit addresses.
- From 00400H - , software BIOS routines for managing KBD, Display, Disk exists.

- The motherboard holds many sockets, slots, chips, connectors.

- To control an I/O device, there exist three levels of Input-Output Control.
- The first level is calling I/O drivers that communicate directly with devices.
- OS security may prevent application-level code from working at this level.
- The second level is calling OS functions for I/O control.
- The third level is calling library functions for I/O control, which may not always be the fastest.
- Assembly Language could perform input-output control on every level 1,2,3 and level 0(Hardware).
'Computer System' 카테고리의 다른 글
| Assembly Language Fundamentals (0) | 2021.04.06 |
|---|---|
| Introduction to Assembly Language (0) | 2021.03.28 |
| System Booting Procedures & I/O Operation Control (0) | 2021.03.19 |
| More about Control Unit & Processor Architectures (0) | 2021.03.12 |
| CPU & Memory & Processor Operation Flow (0) | 2021.03.12 |



