Attention is All You Need
1. 논문 제목 : Attention is All You Need(Transformer)
2. 발표한 학회 : NIPS 2017
3. 논문의 핵심 키워드 : attention mechanisms, multi-head attention, self-attention, Encoder-Decoder
4. 논문요약 :
기존 RNN 기반의 언어 모델들이 가지고 있는 parallelization, vanishing gradient등의 문제점들을 해결하기 위해서 attention mechanism만을 활용한 Encoder-Decoder 모델을 처음 선보인 논문. NLP분야 전반적으로 각 task들을 해결하기 위해 주로 RNN, CNN 기반의 모델들이 활용되는 패러다임을 attention 기반의 모델로 크게 바꾸는 신호탄이 된 논문.
5. 논문에서 소개하는 이전 SOTA / 기존 방법들의 한계:
1) RNN, LSTM, GRU등 recurrence를 기반으로 하는 기존 SOTA 모델들은 sequence의 position에 따라 순차적으로 연산을 진행하여서, 본연적으로 parallelization이 힘들어지게 되고, 긴 sequence 길이를 가진 input을 처리하기 힘들다.
2) 또, CNN에서 convolution을 기반으로 하는 기존 모델들은 sequence input에서 임의의 두 지점 사이의 관계를 연산하는데 있어서, 두 지점 거리가 멀어질 수록 요구되는 연산량이 크게 증가한다는 문제점이 존재하였다.

6. 논문에서 문제점을 해결하기 위해서 사용한 방법론:
1) Sequence Modeling에서 핵심적인 요소로 자리잡게 된 attention mechanism은 연산을 진행하는데 있어서 distance로부터 자유롭다는 특성이 존재한다. 이에 착안하여서 convolution, recurrence 요소를 모두 제외하고 attention mechanism만을 사용한 모델을 설계하면, parallelization을 자유롭게 할 수 있다.
2) Encoder는 multi-head self-attention을 수행하는 layer와 feedforward layer가 한 블록을 이루어서 6개 쌓여있는 구조이다.
3) Decoder는 multi-head self-attention을 수행하는 layer와 Encoder의 output과 Decoder의 input 사이의 관계를 살펴보는 layer, 그리고 feedforward layer가 한 블록을 이루어서 6개 쌓여져있다. 또한, self-attention을 수행할 때 지금 연산하는 position 뒤를 masking하여 미래를 볼 수 없게끔 한다.

4) Attention Mechanism은 query와 (key, value)쌍의 mapping으로 생각할 수 있는데, query와 key가 compatibility function을 통과하여 관련의 정도를 표현하는 matrix에 value를 곱하는 방법으로 이루어진다.
5) 논문에서 사용한 attention 기법은 multiplicative attention(Luong)으로, additive attention(Bahdanau)에 비해 실제로 훨씬 빠르고, 공간을 효율적으로 사용하는 특징이 있다.

6) Multihead Attention은 큰 차원을 가진 key, query, value로 바로 attention 연산을 진행하는 것보다, 여러개의 작은 차원으로 쪼갠뒤에, 각각의 head가 parallel하게 attention 연산을 진행하고, 나중에 각각의 head에서 나온 결과들을 concat한 뒤에 linear projection을 진행하면, 더욱 좋은 결과가 나온다는 것이다.
이는 모델이 각기 다른 위치에서 representation을 attend한 뒤에 나중에 이를 섞는 효과가 있어서 효율적으로 진행되는 것으로 설명하였다.
7) Self Attention은 Encoder, Decoder에 모두 들어 있는 Attention 방법인데, 이는 Multihead Attention과 상반되는 그런 개념이 아니라, key, query, value가 모두 같은 attention 연산을 의미한다.
이를 기반으로 Encoder는 input sequence의 모든 위치를 attend하여 관계성을 분석할 수 있고, Decoder도 자신이 내놓은 output에 대한(masking을 통해 뒤를 가린다) 관계성을 분석하여 다음 output을 정할 수 있다.

8) Self Attention은 3가지 장점을 지니는데,
"임의의 두 위치 사이의 관계성을 분석하기 위한 path length를 상수로 bound 시킬 수 있어, vanishing gradient problem으로부터 자유롭다는 점",
"각각의 layer에 대해서 수행되는 총 연산량이 RNN, CNN기반 모델보다 작다는 점",
"병렬화가 이루어질 수 있는 연산의 총량이 RNN, CNN기반 모델보다 크다는 점"이다.
9) 저자들은 위에서 설명한 architecture에서 Multihead는 8개, 각각의 key, query, value의 차원은 768차원을 사용했다.
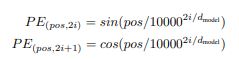
10) input을 하나씩 모델에게 주는 RNN 기반의 모델들과 다르게, Transformer에서는 input을 한번에 모델에게 주기 때문에, 각각의 sequence의 위치 정보를 추가적으로 제공해야했다.
이는 positional encoding이라는 개념을 이용하여 각각의 input에 sequence에서 해당 token의 위치에 대한 sin, cos함수의 진폭을 embedding에 더하는 방법으로 제공하였다.


7. 사용한 데이터셋, 측정한 metric, 학습 진행을 위해서 사용한 hyperparameter, 기존모델대비 성능:
1) 데이터셋 : WMT 2014 English-German dataset / WMT English-French dataset / newstest2013(for ablation studies) / Wall Street Journal portion(WSJ) of Penn Treebank
2) 수행한 task : Machine Translation, English Constituence Parsing
3) 학습을 위해서 사용한 hyperparameter :
vocab size -> 37000 tokens(English-German) / 32000 tokens(English-French)
optimizer -> Adam, beta1=0.9, beta2=0.98, epsilon=10^(-9)
learning-rate -> min(step_num^(-0.5), step_num*warmup_steps^(-1.5)) where warmup_steps=4000
dropout -> rate=0.1
Beam size - > 4, length penalty=0.6
*applied label smoothing
4) 사용한 metric : BLEU(higher the better), F1(higher the better)
5) 기존 모델 대비 성능 향상:
WMT 2014(English->German) : big transformer outperforms previous SOTA more than 2.0 BLEU, establishing 28.4
WMT 2014(English->French) : big transformer outperforms previous SOTA more than 0.51 BLEU, establishing 41.0
WSJ on Penn Treebank : despite lack of task-specific tuning, better results than previous models
(except RNN Grammar model)
8. 추후에 발전할 여지가 있는 점:
1) attention 기반 모델들이 RNN 기반 모델들보다 NLP의 모든 task에 대해서 적용되어서 더욱 좋은 성능을 이끌어 낼 수 있을 것이다.
2) text 뿐만 아니라, 큰 input, output을 가진 image, audio, video와 같은 data도 다룰 수 있게 모델을 변형할 수 있을 것이다.