1. 논문 제목 : PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization
2. 발표한 학회 : PMLR 2020
3. 논문의 핵심 키워드 : Transformers, Abstractive Summarization, Gap-Sentences, ROUGE
4. 논문요약 :
NLP 분야에서 Task들은 크게 두 부류로 나누어 살펴볼 수 있다.
언어에 대한 전반적인 이해를 기반으로 Task에서 요구하는 형식의 Output을 내는 Language Understanding Task와,
언어에 대한 전반적인 이해를 기반으로 다시 자연어, 즉 Text의 형식으로 Output을 내는 Language Generation Task이다.
Language Understanding Task에는 Classification, Parsing, Coreference Resolution, Reading Comprehension등이 있고, BERT와 같은 Encoder 기반의 모델들이 이를 잘 처리하는 것으로 알려져 있다.
반면, Language Generation Task에는 Abstractive Summarization, Machine Translation 등이 존재한다.
Abstractive Summarization은 주어진 Text 내에서 존재하는 Subset으로 요약문을 구성하는 Extractive Summarization과 다르게, 비록 Text 내에는 없을 수는 있지만 보다 자연스러운 문맥을 만들기 위해 새로운 표현들도 추가하여서 요약을 구성하는 Task이다.
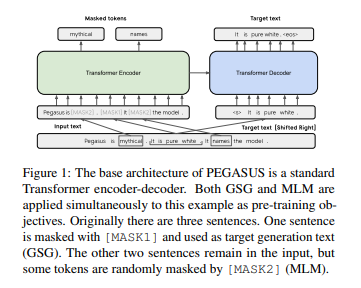
기존의 Language Model들은 Word, 또는 여러개의 Word들을 [MASK]로 부터 유추하는 식으로 구성되어 있었다. 따라서, 문장을 생성해야하는 Abstractive Summarization을 수행할 때는 보다 긴 Sentence 단위로 이를 훈련시키는 것이 좋을 수 있다.
PEGASUS는 Text 내에서 중요한 부분으로 간주되는 부분을 MASK한 뒤에, 이를 복구하는 방법으로 Pretraining을 진행하여서 11가지의 Abstractive Summarization Dataset들에서 좋은 성능을 보여주었다.
5. 스터디 발표 영상 :
https://www.youtube.com/watch?v=_FUXSTK_Xqg&t=1333s
'Natural Language Processing' 카테고리의 다른 글
| Pay Attention to MLPs (0) | 2021.08.16 |
|---|---|
| BIGBIRD : Transformers for Longer Sequences (0) | 2021.08.11 |
| BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (0) | 2021.07.20 |
| RoBERTa : A Robustly Optimized BERT Pretraining Approach (0) | 2021.07.18 |
| MASS : Masked Sequence to Sequence Pre-training for Language Generation (0) | 2021.07.13 |


